- Home ›
- Ruby正規表現の使い方 ›
- 位置の指定 ›
- HERE
文字列の末尾(¥Z, ¥z)
「¥A」は文字列の先頭にだけマッチしましたが、同じように文字列の末尾にだけマッチするものが「¥Z」です。「$」との違いは文字列の中で改行が含まれていたとしても「¥Z」は改行の直前にはマッチしません。
書式は次の通りです。
/パターン¥Z/
具体的な例で考えてみます。「abc¥ndef」と「def¥nabc」と言う2つの文字列に対してパターンを「/abc$/」と指定した場合にはどちらの文字列にも行の末尾に「abc」は含まれているため、どちらもマッチします。
○ abc¥ndef ○ def¥nabc
これに対してパターンを「/abc¥Z/」と記述した場合は、文字列の末尾の位置に「abc」がある場合だけマッチします。よって「abc¥ndef」はマッチしませんが「def¥nabc」はマッチします。
× abc¥ndef ○ def¥nabc
具体的には次のように記述します。
str = "def¥nabc"
if /abc¥Z/ =~ str then
print("マッチします¥n")
else
print("マッチしません¥n")
end
¥Z と ¥z の違い
注意する点として「¥A」とは異なり「¥Z」は文字列の最後が改行で終わっている場合だけは改行の直前にマッチします。
例としてパターンを「/abc¥Z/」と記述した場合は「def¥nabc」だけではなくて「def¥nabc¥n」にもマッチします。
○ def¥nabc ○ def¥nabc¥n
文字列の最後の改行を特別扱いせず、文字列の末尾にだけマッチさせたい場合には「¥Z」の代わりに「¥z」を使います。
書式は次の通りです。
/パターン¥z/
例としてパターンを「/abc¥z/」と記述した場合は「def¥nabc」にはマッチしますが「def¥nabc¥n」にはマッチしません。
○ def¥nabc × def¥nabc¥n
間違えやすい部分でもありますので、注意して利用して下さい。
サンプルプログラム
では簡単なプログラムで確認して見ます。
#! ruby -Ku
require "kconv"
def check1(str)
print(Kconv.tosjis(str + " は abc$ に"))
if /abc$/ =~ str then
print(Kconv.tosjis("マッチします¥n"))
else
print(Kconv.tosjis("マッチしません¥n"))
end
end
def check2(str)
print(Kconv.tosjis(str + " は abc¥¥Z に"))
if /abc¥Z/ =~ str then
print(Kconv.tosjis("マッチします¥n"))
else
print(Kconv.tosjis("マッチしません¥n"))
end
end
def check3(str)
print(Kconv.tosjis(str + " は abc¥¥z に"))
if /abc¥z/ =~ str then
print(Kconv.tosjis("マッチします¥n"))
else
print(Kconv.tosjis("マッチしません¥n"))
end
end
check1("abc¥ndef")
check1("def¥nabc")
check2("abc¥ndef")
check2("def¥nabc")
check2("def¥nabc¥n")
check3("def¥nabc¥n")
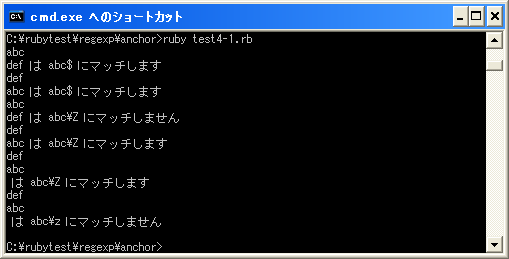
上記のプログラムを「test4-1.rb」として保存します。文字コードはUTF-8です。そして下記のように実行して下さい。
( Written by Tatsuo Ikura )
