- Home ›
- Ruby正規表現の使い方 ›
- 正規表現の基本 ›
- HERE
パターンの中のエスケープ処理
パターンの中には任意の文字を記述することが出来ますが、メタ文字と呼ばれる特殊な用途で使用される文字にはエスケープ処理が必要となります。
¥ * + . ? { } ( ) [ ] ^ $ - | /
これらの文字はパターンの中で使用されると特別な意味を持ちます。そこで単なる文字として扱いたい場合には「¥」記号を使ってエスケープ処理を行います。例えば次のように記述します。
¥¥ ¥* ¥|
また「-」については[]の中で使用される場合にだけ特別な意味を持つため、[]の中で使用される時にエスケープ処理が必要となります。
エスケープシーケンス
正規表現オブジェクトのパターンではバックスラッシュ記法を使ったエスケープシーケンスも記述出来ます。
¥t タブ ¥n 改行 ¥r キャリッジリターン ¥f 改ページ ¥b バックスペース ¥e エスケープ ¥s 空白 ¥nnn 8 進数表記 ¥xnn 16 進数表記 ¥cx コントロール文字 (x は ASCII 文字) ¥C-x コントロール文字 (x は ASCII 文字)
他にも特別な意味を持つエスケープシーケンスが用意されていますが、必要になった時に随時解説していきます。
Regexp.escape(string[,kcode])
Regexpクラスではメタ文字をエスケープした結果を返してくれるクラスメソッドの「escpae」が用意されています。
Regexp.escape(string[,kcode])
1番目の引数にメタ文字が含まれる文字列を指定します。「escape」メソッドは文字列に含まれるメタ文字の前に「¥」記号を挿入したものを返してくれます。例えば「Regexp.escape(".")」は「¥.」を表す文字列「¥¥.」を返します。
2番目の引数には文字コードを指定します(省略可能)。指定可能な値は以下のいずれかの文字列です。
"N" or "n" # None "E" or "e" # EUC-JP "S" or "s" # Shift_JIS "U" or "y" # UTF-8
省略された場合は「$KCODE」に設定された値が使用されます。
「escape」メソッドで取得した文字列を「new」メソッド又は「compile」メソッドの1番目の引数に指定して利用します。
Regexp.new(Regexp.escape("a[b]c"))
これは次のように記述した場合と同じです。
Regexp.new("a¥¥[b¥¥]c")
/a¥[b¥]c/
なお、「escape」メソッドのエイリアスとして「quote」メソッドも用意されています。
Regexp.quote(string[,kcode])
使い方は「escape」メソッドと同じです。
サンプルプログラム
では簡単なプログラムで確認して見ます。
#! ruby -Ku
require "kconv"
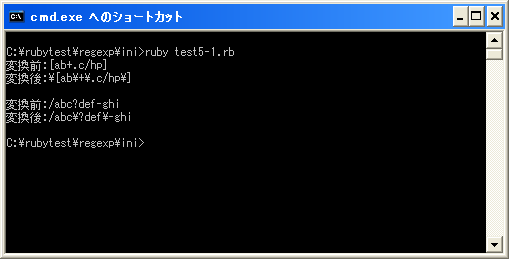
print(Kconv.tosjis("変換前:[ab+.c/hp]¥n"))
print(Kconv.tosjis("変換後:") + Regexp.escape("[ab+.c/hp]") + "¥n")
print("¥n")
print(Kconv.tosjis("変換前:/abc?def-ghi¥n"))
print(Kconv.tosjis("変換後:") + Regexp.escape("/abc?def-ghi") + "¥n")
上記のプログラムを「test5-1.rb」として保存します。文字コードはUTF-8です。そして下記のように実行して下さい。
( Written by Tatsuo Ikura )
