- Home ›
- Ruby正規表現の使い方 ›
- Ruby正規表現における日本語の扱い ›
- HERE
正規表現オブジェクトの文字コードの指定
正規表現オブジェクトを使って文字列とのマッチを行う場合、文字列の文字コードは「$KCODE」で設定されている文字コードを使ってマッチするかどうかを行います。(「$KCODE」については「日本語と文字コード」を参照して下さい)。
「$KCODE」に設定が行われていない場合、デフォルトの値は「NONE(ASCII)」ですので日本語を取り扱うことは出来ません。「SJIS」「EUC」「UTF-8」のいずれかの文字コードを設定しておく必要があります。
通常は「$KCODE」に使用する文字コードを事前に設定しておけばいいのですが、正規表現を使用する場合だけ文字コードを別のものに指定することも出来ます。この場合は次のように正規表現オブジェクトを作成します。
/パターン/文字コード
文字コードとして指定可能な値は次のいずれかです。
"N" or "n" # None "E" or "e" # EUC-JP "S" or "s" # Shift_JIS "U" or "y" # UTF-8
例えばUTF-8を使ってマッチするかどうかを行う場合には次のように正規表現オブジェクトを作成します。
/パターン/u
これで「$KCODE」に設定された値に関わらず文字列の文字コードがUTF-8としてマッチングが行われます。
Regexp.newメソッドを使って正規表現オブジェクトを作成する場合
Regexpクラスのクラスメソッドである「new」メソッド又は「compile」メソッドを使って正規表現オブジェクトを作成することも可能です。
Regexp.new(string[, option[, code]])
この時、3番目の引数で使用する文字コードを指定することが出来ます。文字コードとして指定できる値は先ほどと同じです。例えば文字コードに「UTF-8」を指定する場合は次のように記述します。
Regexp.new("パターン文字列", nil, "u")
3番目の引数を指定する場合は2番目の引数を省略できません。2番目の引数であるオプションに何も指定しない場合は「nil」を指定して下さい。
サンプルプログラム
では簡単なプログラムで確認して見ます。
#! ruby -Ku
require "kconv"
def check(str)
if /入門/u =~ str then
print(Kconv.tosjis("○" + str + "¥n"))
else
print(Kconv.tosjis("×" + str + "¥n"))
end
end
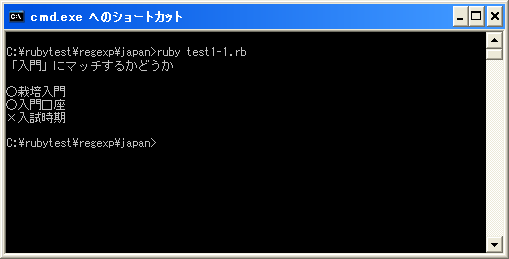
print(Kconv.tosjis("「入門」にマッチするかどうか¥n¥n"))
check("栽培入門")
check("入門口座")
check("入試時期")
上記のプログラムを「test1-1.rb」として保存します。文字コードはUTF-8です。そして下記のように実行して下さい。
( Written by Tatsuo Ikura )
